삼성전자 주가 예측 모델: LSTM을 이용한 시계열 예측
이번 포스트에서는 삼성전자 주가 데이터를 이용해 시계열 예측을 수행하는 간단한 LSTM(Long Short-Term Memory) 모델을 구축하고, 이를 통해 미래의 주가를 예측하는 방법을 소개합니다. 이 과정에서 사용한 코드는 Python의 TensorFlow 및 Keras 라이브러리를 활용하였으며, 데이터는 yfinance 라이브러리를 통해 Yahoo Finance에서 다운로드했습니다.
1. 데이터 다운로드 및 전처리
우선, yfinance 라이브러리를 이용하여 삼성전자(종목 코드: 036570.KS)의 주가 데이터를 다운로드합니다. 데이터는 2022년 1월 1일부터 2024년 8월 28일까지의 기간을 대상으로 하였습니다.
import yfinance as yf
raw_df = yf.download('036570.KS', start='2022-01-01', end='2024-08-28')
print(raw_df.columns)다운로드한 데이터의 열(columns)은 'Open', 'High', 'Low', 'Close', 'Volume' 등이 포함되며, 이 중에서 모델 입력으로 사용할 변수들을 선택하고, 정규화 과정을 거쳐 모델에 적합한 형태로 변환합니다.
2. Min-Max 스케일링
데이터를 신경망 모델에 입력하기 전에, 각 변수의 값을 0과 1 사이로 정규화합니다. 이를 위해 Min-Max 스케일링을 사용합니다.
def MinMaxScaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
return numerator / (denominator + 1e-7)이 함수는 데이터의 최소값과 최대값을 이용하여 각 값을 0과 1 사이의 값으로 변환합니다. 이 과정을 통해 데이터의 스케일 차이가 모델 학습에 미치는 영향을 줄일 수 있습니다.
3. 데이터셋 생성
이제 시계열 데이터에서 LSTM 모델을 훈련시키기 위한 입력과 출력을 생성합니다.
dfx = raw_df[['Open', 'High', 'Low', 'Close', 'Volume']]
dfx = MinMaxScaler(dfx)
dfy = dfx[['Close']]
x = dfx.values.tolist()
y = dfy.values.tolist()
data_x = []
data_y = []
window_size = 10
for i in range(len(y) - window_size):
_x = x[i : i + window_size]
_y = y[i + window_size]
data_x.append(_x)
data_y.append(_y)
print(_x, "->", _y)위 코드에서 window_size는 LSTM 모델에 입력되는 시퀀스의 길이를 의미합니다. window_size 만큼의 데이터를 입력으로 사용해 다음 날의 주가를 예측하는 방식으로 데이터를 구성합니다.
4. 데이터셋 분리
훈련 데이터와 테스트 데이터를 나누어 모델의 성능을 평가할 수 있도록 준비합니다.
dfx = raw_df[['Open', 'High', 'Low', 'Close', 'Volume']]
dfx = MinMaxScaler(dfx)
dfy = dfx[['Close']]
x = dfx.values.tolist()
y = dfy.values.tolist()
data_x = []
data_y = []
window_size = 10
for i in range(len(y) - window_size):
_x = x[i : i + window_size]
_y = y[i + window_size]
data_x.append(_x)
data_y.append(_y)
print(_x, "->", _y)전체 데이터셋의 70%는 훈련에 사용되고, 나머지 30%는 테스트에 사용됩니다.
5. LSTM 모델 구축
이제 LSTM 모델을 구축합니다. 이 모델은 두 개의 LSTM 층과 드롭아웃 층으로 구성되어 있습니다.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
model = Sequential()
model.add(LSTM(units=10, activation='relu', return_sequences=True, input_shape=(window_size, 5)))
model.add(Dropout(0.1))
model.add(LSTM(units=10, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=1))
model.summary()- LSTM 층: 시계열 데이터의 패턴을 학습합니다. 첫 번째 LSTM 층은 return_sequences=True로 설정되어 다음 LSTM 층에 시퀀스를 반환합니다.
- Dropout 층: 과적합을 방지하기 위해 일부 뉴런을 무작위로 제외시킵니다.
- Dense 층: 마지막 출력 층으로, 다음 날의 주가를 예측합니다.
6. 모델 훈련 및 예측
모델을 컴파일하고 훈련시킨 후, 테스트 데이터를 사용해 주가를 예측합니다.
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(train_x, train_y, epochs=60, batch_size=30)
pred_y = model.predict(test_x)60번의 에포크 동안 모델을 훈련시킨 후, 테스트 데이터로 예측을 수행합니다.
7. 결과 시각화
예측한 결과를 실제 주가와 비교하여 시각화합니다.
import matplotlib.pyplot as plt
plt.figure()
plt.plot(test_y, color='red', label='real PEP stock price')
plt.plot(pred_y, color='blue', label='predicted PEP stock price')
plt.title('PEP stock price prediction')
plt.xlabel('time')
plt.ylabel('stock price')
plt.legend()
plt.show()8. 미래 주가 예측
마지막으로, 모델을 사용해 다음 날과 그 다음 날의 주가를 예측합니다.
tomorrow_price = raw_df['Close'].iloc[-1] * pred_y[-2] / dfy['Close'].iloc[-1]
day_after_tomorrow_price = raw_df['Close'].iloc[-1] * pred_y[-1] / dfy['Close'].iloc[-1]
print("PEP tomorrow's price:", tomorrow_price)
print("PEP day after tomorrow's price:", day_after_tomorrow_price)9. 전체 코드 및 결과
다음은 전체 코드입니다.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
raw_df = yf.download('036570.KS', start='2022-01-01', end='2024-08-28')
print(raw_df.columns)
def MinMaxScaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
return numerator / (denominator + 1e-7)
dfx = raw_df[['Open', 'High', 'Low', 'Close', 'Volume']]
dfx = MinMaxScaler(dfx)
dfy = dfx[['Close']]
x = dfx.values.tolist()
y = dfy.values.tolist()
data_x = []
data_y = []
window_size = 10
for i in range(len(y) - window_size):
_x = x[i : i + window_size]
_y = y[i + window_size]
data_x.append(_x)
data_y.append(_y)
print(_x, "->", _y)
train_size = int(len(data_y) * 0.7)
train_x = np.array(data_x[0 : train_size])
train_y = np.array(data_y[0 : train_size])
test_size = len(data_y) - train_size
test_x = np.array(data_x[train_size : len(data_x)])
test_y = np.array(data_y[train_size : len(data_y)])
model = Sequential()
model.add(LSTM(units=10, activation='relu', return_sequences=True, input_shape=(window_size, 5)))
model.add(Dropout(0.1))
model.add(LSTM(units=10, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=1))
model.summary()
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(train_x, train_y, epochs=60, batch_size=30)
pred_y = model.predict(test_x)
plt.figure()
plt.plot(test_y, color='red', label='real PEP stock price')
plt.plot(pred_y, color='blue', label='predicted PEP stock price')
plt.title('PEP stock price prediction')
plt.xlabel('time')
plt.ylabel('stock price')
plt.legend()
plt.show()
tomorrow_price = raw_df['Close'].iloc[-1] * pred_y[-2] / dfy['Close'].iloc[-1]
day_after_tomorrow_price = raw_df['Close'].iloc[-1] * pred_y[-1] / dfy['Close'].iloc[-1]
print("PEP tomorrow's price:", tomorrow_price)
print("PEP day after tomorrow's price:", day_after_tomorrow_price)
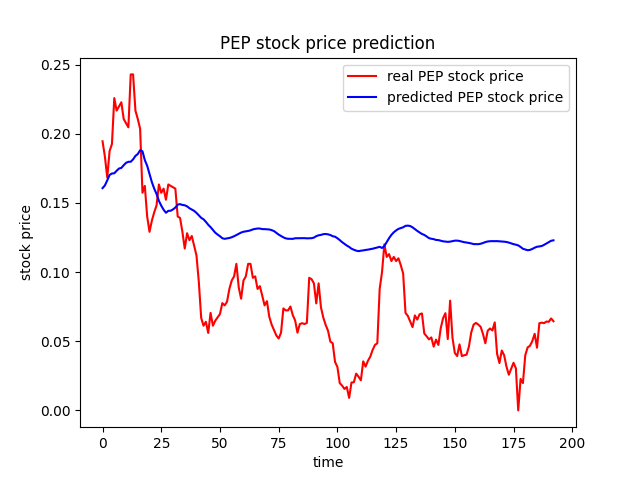
결론
이 블로그 포스트에서는 LSTM 모델을 사용해 삼성전자 주가를 예측하는 방법을 살펴보았습니다. 시계열 데이터의 패턴을 학습하여 미래의 주가를 예측하는 데 효과적인 방법이지만, 실제 주식 시장에서의 예측은 매우 어렵고 불확실성이 크므로 주의가 필요합니다. 이 모델을 기반으로 다양한 변수와 방법을 추가하여 더 정교한 예측 모델을 개발할 수 있을 것입니다.